
Intel uvádí Alder Lake / Core 12000, aneb velká a malá jádra v akci

Největší procesorová událost letošního roku je tu, Intel představil procesory Alder Lake a detailnější informace k tomu, jak budou využívána velká a malá jádra. Je to velmi zajímavé…
Jak již bylo avizováno, recenze a zahájení prodejů nastane až 4. listopadu. To však nic nemění na množství zajímavých informací, které se o Alder Lake dozvídáme. Především o řízení spotřeby a řízení zátěže, což jsou dva okruhy, na které se dnes podíváme. Začněme ale u specifikací, i ty jsou nakonec trochu jiné.
V první řadě platí, že v letošním roce Intel vydává tři základní 125W modely („K“), respektive šest, pokud variantu s vypnutou grafikou počítáme jako samostatný model. 65W modely přijdou příštím roce. V tabulce nechávám i jejich částečné specifikace - podžlucené procesory jsou Alder Lake, tučně vyznačené aktuálně představené novinky:
| od. | jád. vlák. | takt | L3 | GPU | TDP | cena | |
|---|---|---|---|---|---|---|---|
| Core i9-12900K | 8+8/24 | 3,2 / 5,2 GHz 2,4 / 3,9 GHz | 30MB | 125W 241W | $589 | ||
| Core i9-12900KF | 8+8/24 | 3,2 / 5,2 GHz | 30MB | 125W 241W | $564 | ||
| Core i9-11900K | 8 / 16 | 3,5 / 5,3 GHz | 16MB | 125W | $539 | ||
| Core i9-11900KF | 8 / 16 | 3,5 / 5,3 GHz | 16MB | 125W | $513 | ||
| Core i9-12900 | 8+?/? | ? | ? | 65W | ? | ||
| Core i9-12900F | 8+?/? | ? | ? | 65W | ? | ||
| Core i9-11900 | 8 / 16 | 2,5 / 5,2 GHz | 16MB | 65W | $439 | ||
| Core i9-11900F | 8 / 16 | 2,5 / 5,2 GHz | 16MB | 65W | $422 | ||
| Core i9-11900T | 8 / 16 | 1,5 / 4,9 GHz | 16MB | 35W | $439 | ||
| Core i7-12700K | 8+4/20 | 3,6 / 5,0 GHz 2,7 / 3,8 GHz | 25MB | 125W 190W | $409 | ||
| Core i7-12700KF | 8+4/20 | 3,6 / 5,0 GHz | 25MB | 125W 190W | $384 | ||
| Core i7-11700K | 8 / 16 | 3,6 / 5,0 GHz | 16MB | 125W | $399 | ||
| Core i7-11700KF | 8 / 16 | 3,6 / 5,0 GHz | 16MB | 125W | $374 | ||
| Core i7-12700 | 8+?/? | ? | ? | 65W | ? | ||
| Core i7-12700F | 8+?/? | ? | ? | 65W | ? | ||
| Core i7-11700 | 8 / 16 | 2,5 / 4,9 GHz | 16MB | 65W | $323 | ||
| Core i7-11700F | 8 / 16 | 2,5 / 4,9 GHz | 16MB | 65W | $298 | ||
| Core i7-11700T | 8 / 16 | 1,4 / 4,6 GHz | 16MB | 35W | $323 | ||
| Core i5-12600K | 6+4/16 | 3,7 / 4,9 GHz 2,8 / 3,6 GHz | 20MB | 125W 150W | $289 | ||
| Core i5-12600KF | 6+4/16 | 3,7 / 4,9 GHz | 20MB | 125W 150W | $264 | ||
| Core i5-11600K | 6 / 12 | 3,9 / 4,9 GHz | 12MB | 125W | $262 | ||
| Core i5-11600KF | 6 / 12 | 3,9 / 4,9 GHz | 12MB | 125W | $237 | ||
| Core i5-11600 | 6 / 12 | 2,8 / 4,9 GHz | 12MB | 65W | $213 | ||
| Core i5-11600T | 6 / 12 | 1,7 / 4,1 GHz | 12MB | 35W | $213 | ||
| Core i5-11500 | 6 / 12 | 2,7 / 4,6 GHz | 12MB | 65W | $192 | ||
| Core i5-11500T | 6 / 12 | 1,5 / 3,9 GHz | 12MB | 35W | $192 | ||
| Core i5-12400 | 6+?/? | ? | ? | 65W | ? | ||
| Core i5-12400F | 6+?/? | ? | ? | 65W | ? | ||
| Core i5-11400 | 6 / 12 | 2,6 / 4,4 GHz | 12MB | 65W | $182 | ||
| Core i5-11400F | 6 / 12 | 2,6 / 4,4 GHz | 12MB | 65W | $157 | ||
| Core i5-11400T | 6 / 12 | 1,3 / 3,7 GHz | 12MB | 35W | $182 | ||
| Core i3-12100 | 4+?/? | ? | ? | 65W? | ? |
V první řadě stojí za pozornost, že Core i9 má nepatrně snížený boost oproti výkonnostním únikům. Maximum není 5,3 GHz, ale 5,2 GHz. Boostové hodnoty, které jsme uváděli v předchozích článcích, s touto výjimkou platí a jsou oficiálně potvrzeny. Jak už bylo mnohokrát řečeno, procesory Alder Lake se skládají z velkých (P / Golden Cove) jader a malých (E / Gracemont / Atom) jader. V tabulce jsou vždy uvedeny nejprve údaje pro velká jádra, pak pro malá. Údaj 8+4/20 tedy znamená 8 velkých jader, 4 malá a celkem 20 vláken (16 vláken obstarávají velká jádra, 4 malá). Stejně tak frekvence: nejprve základní takt / boost velkých jader, pak základní takt / boost malých.
Uvedené ceny, jak je u Intelu obvyklé, se týkají velkoobjemových dodávek (nad 1000 kusů), takže realita koncových prodejců může být (v závislosti na jejich maržích a v našich končinách i s ohledem na kurzy a DPH) trochu jiná. Alza.cz v okamžiku vzniku tohoto textu uvádí následující předobjednávkové ceny včetně DPH (CZC ceny neuvádí):
- Core i9-12900K - 18 990,-
- Core i9-12900KF - 17 990,-
- Core i7-12700K - 12 990,-
- Core i7-12700KF - 11 990,-
- Core i5-12600K - 8 999,-
- Core i5-12600KF - 7 999,-
Navzdory, že oficiálními cenami je např. Core i9-12900K podstatně blíže Ryzenu 9 5900X než Ryzenu 9 5950X reálnými cenami se více blíží rychlejšímu modelu. Stejně tak zatímco Core i7-12700K je oficiální cenou pod Ryzenem 7 5800X, reálnou cenou se blíží spíše Ryzenu 9 5900X (Alza / nejnižší cena dle Heureky):
- Ryzen 9 5950X - 20 390,- / 20 281,-
- Ryzen 9 5900X - 14 290,- / 13 590,-
- Ryzen 7 5800X - 10 990,- / 10 398,-
- Ryzen 7 5700G - 8 890,- / 8 940,-
- Ryzen 5 5600X - 7 990,- / 7 689,-
- Ryzen 5 5600G - 6 390,- / 6 899,-
Jako cenově zajímavé se tak jeví hlavně Core i5-12600KF, které při stejné ceně dosahuje podle uniklých testů podstatně vyššího výkonu než Ryzen 5 5600X. Naopak z pohledu spotřeby (65W vs. 125W TDP, respektive 88W vs. 150W limit) a cenového srovnání Core i5-12600K nevychází při částce téměř o polovinu vyšší tak zajímavě jako Ryzen 5 5600G.
Spotřeba, řízení spotřeby a (o něco) transparentnější marketing
Samostatnou kapitolu si zaslouží energetická stránka. Intel s generacemi Coffee Lake, Coffee Lake-refresh, Comet Lake a Rocket Lake vytvořil z TDP hodnotu, která se generace od generace více a více vzdalovala od reálné spotřeby v zátěži. Rostoucí energetické nároky více-méně skrýval pod údajem, který nijak neodpovídal reálnému chování procesoru a komplikoval tím jak srovnání s konkurencí, tak s vlastními produkty jiných generací, tak i výběr dostačujícího zdroje a chladiče. TDP u Intelu znamenalo spotřebu při základním taktu (bez jakéhokoli boostu) v zátěži definované Intelem. Procesor ale reálně boostoval a mohl si brát až násobně více energie, než uvádělo TDP. Původně to platilo pro krátkodobý (několikasekundový) boost, později (zhruba s výše jmenovanými generacemi) se časový limit tohoto boostu prodloužil až zhruba na minutu a nakonec Intel - v rozporu s veřejně dostupnou dokumentací - nabádal výrobce základních desek, aby časový limit vypnuli, tedy ponechali boost při vyšší spotřebě nekonečně dlouhý. Případně vypnuli i samotný limit spotřeby.
S generací Alder Lake se Intel konečně snaží být transparentnější a co je popsáno výše, otevřeně přiznává a zařazuje do základních specifikací produktu. Spotřebu nově popisují dvě hodnoty: Ta, která byla dosud uváděna pod označením TDP a která se týká běhu na základním taktu, se nově jmenuje „base“ a ta, která se týká běhu na vyšších taktech (PL2), se jmenuje „boost“. Proto například u Core i9-12900K čteme údaje 125 a 241 wattů.

Zároveň s tím Intel otevřeně stanovil, že pro nyní vydané procesory (řada „K“) bude časový limit ve výchozím stavu vypnutý (situace na slajdu zcela vpravo). Jinými slovy PL2 limit alias „boost“ je časově neomezený (což naznačuje, že u 65W by mohl být aktivní - uvidíme). Kombinací těchto dvou skutečností (stanovením a zveřejněním horního limitu + otevřeným prohlášením o absenci časového omezení) se Intel co do transparentnosti specifikace posunul na úroveň AMD, která například u Ryzen 9 5900X specifikuje TDP 105 wattů a limit 142 wattů.
Může to však svádět ke stavění hodnot AMD a Intelu na stejnou úroveň, což by pravděpodobně nebylo zcela korektní. Totiž, zatímco u Intelu nadále platí, že nižší hodnota spotřeby se týká čistě základního taktu, u AMD se do této hodnoty vejde i nějaký základní boost (pokud např. osadíme nové procesory do starých AM4 desek, které vyšší režimy boostu nepodporují, stále budou i při nižším limitu spotřeby základního boostu dosahovat).
To je jeden aspekt, který se týká definice hodnot. Druhý a odlišný se týká výše samotných hodnot - Intel je transparentnější, což je pozitivní, ovšem samo o sobě to nic nemění na faktu, že hodnoty limitů spotřeby jsou stále velmi vysoké. Například oba současné Ryzeny 9 59x0X mají limit spotřeby 142 wattů, zatímco nové Core i9-12900K(F) 241 wattů, tedy prakticky o stovku výše.

Navzdory tomu se energetická efektivita značně zlepšila. Intel uvádí, že Core i9-12900K uměle limitované na 65 wattů dosahuje výkonu Core i9-11900K na 250 wattech. Zvýšení energetické efektivity odpovídající násobku 3,85× je však jen zdánlivé, neboť sníženým energetickým limitem podtaktované Core i9-12900K běží ve zcela jiné části křivky závislosti spotřeby na taktovacích frekvencích, než v jaké bude běžet při továrním nastavení. Jinak řečeno, i kdybychom podtaktovali „staré“ Core i9-11900K, taky mu stoupne energetické efektivita. Objektivní srovnání je tedy potřeba provést na obou procesorech v továrním nastavení, nikoli zvýhodněním jednoho posunutím taktů do energetického optima. Takže zde je stále cítit silná marketingová snaha postavit produkt do lepšího světla, než ve kterém reálně stojí. Čímž samozřejmě nepopírám, že k citelnému zlepšení došlo (jak citelnému, řeknou až listopadové recenze).
Scheduler, aneb jak rozložit zátěž mezi velká a malá jádra
Jak již bylo rovněž mnohokrát řečeno, integrují procesory Alder Lake hardwarový obvod nazvaný Intel Thread Director. Ten v základním stavu (co si pod těmito slovy představit, vysvětlím o pár odstavců níže) de facto rozhoduje o tom, které zátěž a jaké její vlákno poběží na kterém (velkém / malém…) jádru. V tomto základním stavu funguje situace v základních rysech podobně (byť výrazně složitěji) jako jsme ji popisovali po vydání procesorů Zen 2: Operační systém Windows má sice ponětí o tom, že některá jádra mohou být rychlejší, ale detailní informace o architektuře, jejích specifikách a limitech nemá, takže výrobce procesoru si hraje na loutkovodiče, který taháním za nitky přiměje scheduler operačního systému Windows (loutku) přiřazovat vlákna tak, jak je pro procesor výhodné.
V případě Zen 2 (platí i pro Zen 3) byla situace podstatně jednodušší a stačilo předáním fixních údajů o frekvencích, kterých jednotlivá jádra procesoru dosahují, scheduler přimět, aby přiřadil zátěž těm správným jádrům. Údaje o frekvencích neodpovídaly realitě, dokonce ani sled o nejrychlejšího po nejpomalejší neodpovídal skutečnému pořadí rychlosti jader. Protože však bylo výhodnější, aby byla nejprve využívána jádra umístěná v procesoru fyzicky u sebe (sdílející společnou L3 cache = nižší vzájemné latence), tvářila se tato jádra jako o něco rychlejší než ve skutečnosti, aby je scheduler Windows upřednostňoval.

Alder Lake v tomto musí jít podstatně dál, protože je potřeba řešit dvě procesorové architektury - tedy dvě skupiny jader s podstatně odlišným výkonem. Zde nestačí řešení jaké pro preferenci nestejně rychlých jader zvolila AMD. Alder Lake proto obsahuje hardwarový obvod (Intel Thread Director), který sám (na základě scénářů natrénovaných pomocí strojového učení) situaci vyhodnocuje a posílá takové údaje scheduleru Windows, které jej přimějí rozložit zátěž tak, jak Intel Thread Director považuje za optimální.
Vše, co bylo až potud popsáno v této kapitole, platí pro onen zmíněný základní stav (nejde o označení Intelu, ale o pracovní označení pro potřeby tohoto článku). Tím je míněna situace, kdy standardní software, který neobsahuje specifické optimalizace pro Alder Lake (tj. >99 % stávajícího softwaru) běží na sestavě s procesorem Alder Lake a operačním systémem Windows 11 a zároveň do rozložení zátěže (např. změnami priority ve správci úloh / task manageru) nezasahuje uživatel. V takové situaci scheduler Windows skutečně vychází z rozhodnutí, která za něj již udělal Intel Thread Director a mechanizmus řízení zátěže funguje stylem loutkovodič (ITD) - loutka (scheduler Windows).
Jak z tohoto popisu vyplývá, mohou ale nastat i jiné situace. V první řadě do situace může vstupovat software. Ten může nabývat tří stavů, jimž jsme se již věnovali v jednom z předchozích článků. Buďto není vůbec optimalizovaný (první bod - pak platí, co bylo řečeno výše), nebo obsahuje menší či větší míru optimalizací, za jejichž existence přebírá část loutkovodičských nitek právě aplikace. Jinými slovy scheduler Windows nebude rozhodovat podle vstupů od Intel Thread Director, ale zohlední i požadavky / data od aplikace (2. a 3. bod).
- No optimizations - situace, kdy na procesoru běží standardní aplikace, která neobsahuje specifické optimalizace pro tuto architekturu. Rozložení zátěže mezi velká a malá jádra záleží čistě na tom, jak situaci vyhodnotí hardwarový obvod (který závěry svého algoritmu předá operačnímu systému). Může docházet k situacím, kdy vedlejší úloha poběží na velkém jádru nebo naopak klíčové úloha na malém.
- „Good“ scenario - situace, kdy vývojář podnikne základní kroky k optimalizaci úlohy pro Alder Lake. Obnáší vytvoření systému úloh na základě počtu velkých jader nebo maximálního počtu vláken (cílících na velká jádra) klíčových pro úlohu a nastavení priority (vysoká / nízká) vláken přes QoS API, aby tato vlákna cílila na správná jádra.
- „Best scenario“ - vytvoření dvou skupin vláken („hybrid-aware tasking system“), kdy první skupina cílí na výkonná jádra a sekundární (např. kompilace shaderů, mixování zvuku, dekomprese a další úlohy, které nejsou kritické pro výsledný výkon).
Do rozložení zátěže však nemusí vstupovat jen optimalizace softwaru, ale také uživatel. A to hned v několika rovinách. Příklady dvou hlavních:
(1) Může jít o zásah uživatele ve správci úloh (nebo jiném podobném nástroji), jimž například aplikaci sníží prioritu. Takový zásah může vést např. k přesunutí zátěže z velkých jader na malá.
(2) Příkladem druhé je (řekněme) nevědomý zásah uživatel. Ačkoli možná bude znít zvláštně, skutečně takto Intel chování systému popisuje: Přestavte si situaci, kdy nějaká náročnější aplikace ve Windows běží v aktivním okně na velkých jádrech. Pouhé překliknutí na jiné ono automaticky sníží prioritu neaktivnímu oknu a zátěž je následkem toho převedena na malá jádra. Podle Intelu si tento mechanizmus vyžádal Microsoft. Takové chování může být vhodnější z energetického hlediska, ale těžko z uživatelského. Pokud například spustím rendering nebo kompresi videa, která poběží třeba hodinu a během tohoto času si chci přečíst zprávy na internetu, stane se aktivním oknem okno prohlížeče a zátěž, na kterou čekám, se mi přesune na malá jádra, na nichž poběží (třeba) 2× tak dlouho.
Pokud skutečně v praxi bude situace fungovat tak, jak popisuje Intel a jak si vyžádal Microsoft, bude si buďto uživatel muset sám ladit prioritu aplikací, aby se mu rendering / komprese / kompilace… na pozadí nezpomalila převodem na malá jádra. Nebo Microsoft s Intelem budou muset situaci přehodnotit a nastavit výchozí chování jinak, neboť by mimo benchmarky (které běží v aktivním okně) byl procesor reálně pomalejší než cokoli vydaného za poslední 3-4 roky (výkon by byl degradován doslova na výkon 4-8jádrového Atomu, protože by aplikace fakticky běžela na 4-8jádrovém Atomu).
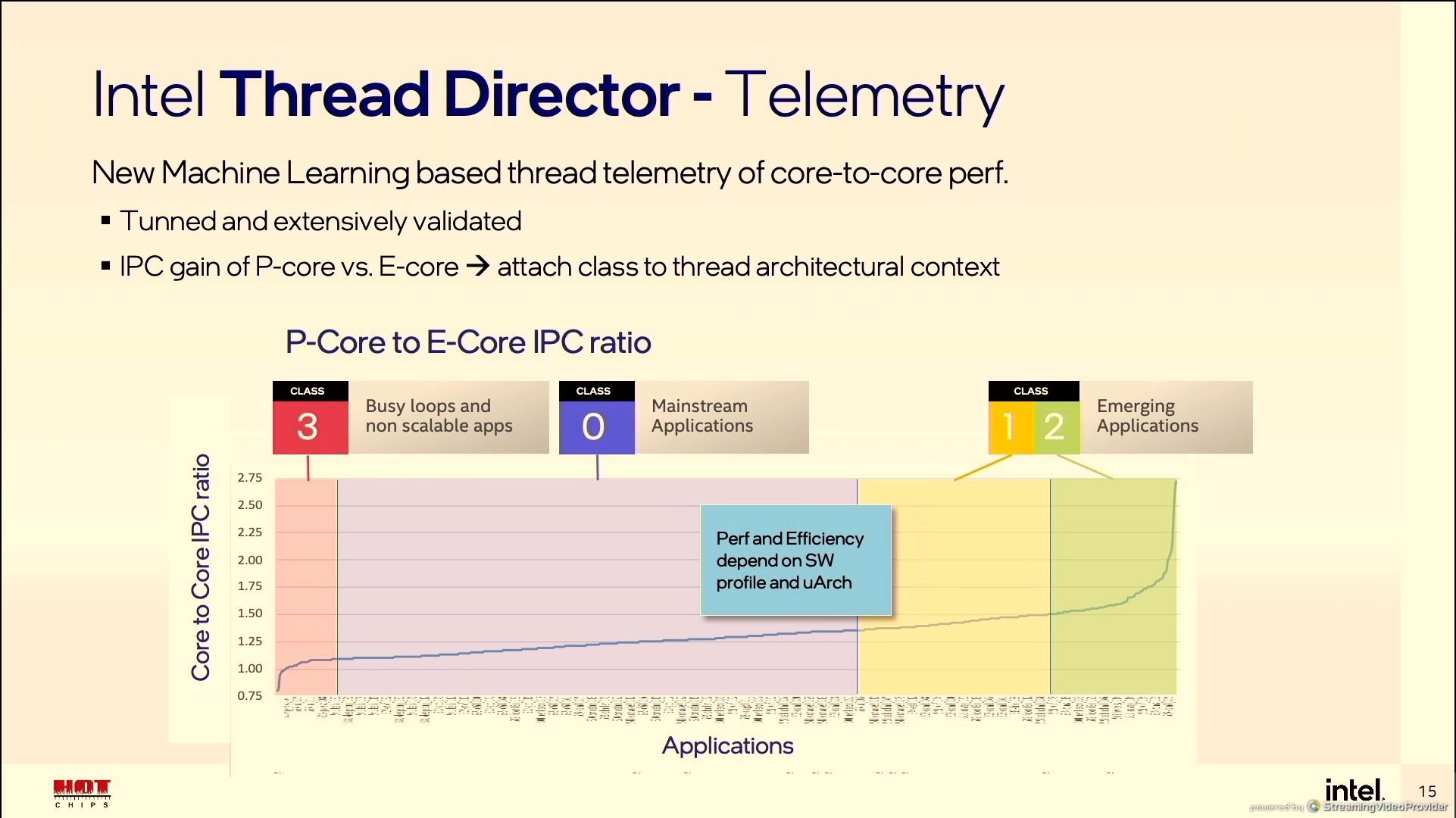
Pokud jde o základní rozdělování zátěže v automatickém režimu (bez vstupů optimalizací softwaru a bez vstupů uživatele), počítá se s čtyřmi stavy:
| třída | popis | primárně přiřazená jádra |
|---|---|---|
| Class 3 | limitem výkonu není výpočetní výkon, jde o IO operace, zaneprázdněné smyčky a jiné úlohy, které neškálují | E-jádra (malá) |
| Class 2 | zátěže využívající AVX-VNNI | P-jádra (velká) |
| Class 1 | zátěže využívající AVX/AVX2 | P-jádra (velká) |
| Class 0 | vše, co nespadá do ostatních tříd | * |
*u třídy „0“ je pak dále algoritmy rozhodováno, jaká jádra budou využita a v případě přiřazení velkých je úpravou frekvence laděna energetická efektivita a efektivní IPC. U všech čtyř tříd může uživatel úpravou priority do mechanizmu zasáhnout.
Pro představu o komplexnosti celé situace musíme brát v potaz, že nejde pouze o rozdělování zátěže mezi velká a malá jádra, ale Intel Thread Director (není-li vstup od aplikace nebo uživatele) dále řeší dilema, zda například po jednovláknovém vytížení všech velkých jader bude další vlákna delegovat na Atomy (malá jádra), nebo jako druhá vlákna velkých jader.
Při složitosti této problematiky pak přichází řada otázek, na které dosud není uspokojivá odpověď (což znamená, že i nějaká odpověď může existovat, ale z uživatelského hlediska nemusí být uspokojivá). Modelový příklad zmínila redakce webu Anandtech: Existují případy, kdy aktivní okno aplikace, ve kterém pracujeme s nějakou velkou procesorovou zátěží, je ve skutečnosti pouze GUI (uživatelské rozhraní), zatímco skutečnou zátěž toto GUI deleguje nějakému procesu na pozadí. V takovém případě poběží grafické rozhraní softwaru s vyšší prioritou (možná na velkých jádrech) a skutečná zátěž bude delegována na malá jádra (protože neběží v aktivním okně).

Na závěr ještě chybí dodat, že roli hraje i verze operačního systému. Zatímco ve Windows 11 je scheduler připraven na efektivní spolupráci s Intel Thread Director, ve Windows 10 scheduler končí u rozdělení na výkonnější a méně výkonná jádra, ale pokročilejší řešení složitějších situací je (bez optimalizací softwaru) nad jeho možnosti. Ve Windows 10 se tak budeme častěji setkávat se situacemi, kdy dojde k méně optimálnímu rozložení zátěže než ve Windows 11.
V tomto kontextu si lze představit celou řadu praktických situací a aplikací, které se z hlediska Intel Thread Director nebudou chovat jako prosté benchmarky běžící v aktivním okně s paralelní zátěží stejného počtu stejně náročných (do zátěže i instrukčního setu) vláken. Vzniká prostor pro řadu situací, ve kterých se Intel Thread Director může - podle popisu Intelu - chovat jinak, než je z uživatelského hlediska očekávatelné a žádané. Na druhou stranu takové situace nemusejí být definitivní a neměnné: Mohou vznikat optimalizace pro jednotlivé aplikace, uživatelé si mohou zvyknout na ruční úpravu priority, Intel třeba zavede aktualizace pro scheduling, které budou nejpalčivější situace řešit třeba v rámci záplat Windows Update.
Zdroje:
Intel, Anandtech





















